
By Jordi Solé Casaramona.
This repository is part of the thesis of the Master’s in Data Science by the University of Barcelona 2019/2020.
This work has been done with the collaboration of the EMEA 3D sales team in HP. The dataset in which the project is based on is currently more than 40,500 leads from the fiscal year 2016 quarter 1 to the fiscal year 2020 quarter 4. On average, every week 257 new leads are entered into the system.
The main objective of this project is to develop a data science pipeline, capable of predicting, for every lead, the quality of it. Meaning quality, the probability in which the lead is going to become a possible sell, and to advance to the next sale stages. By doing this, we want to achieve a transition from decisions based on intuition from the salesman, to more data-driven decision-making with the use of a score, from 0 to 1, that will be an indication of the quality of the lead.
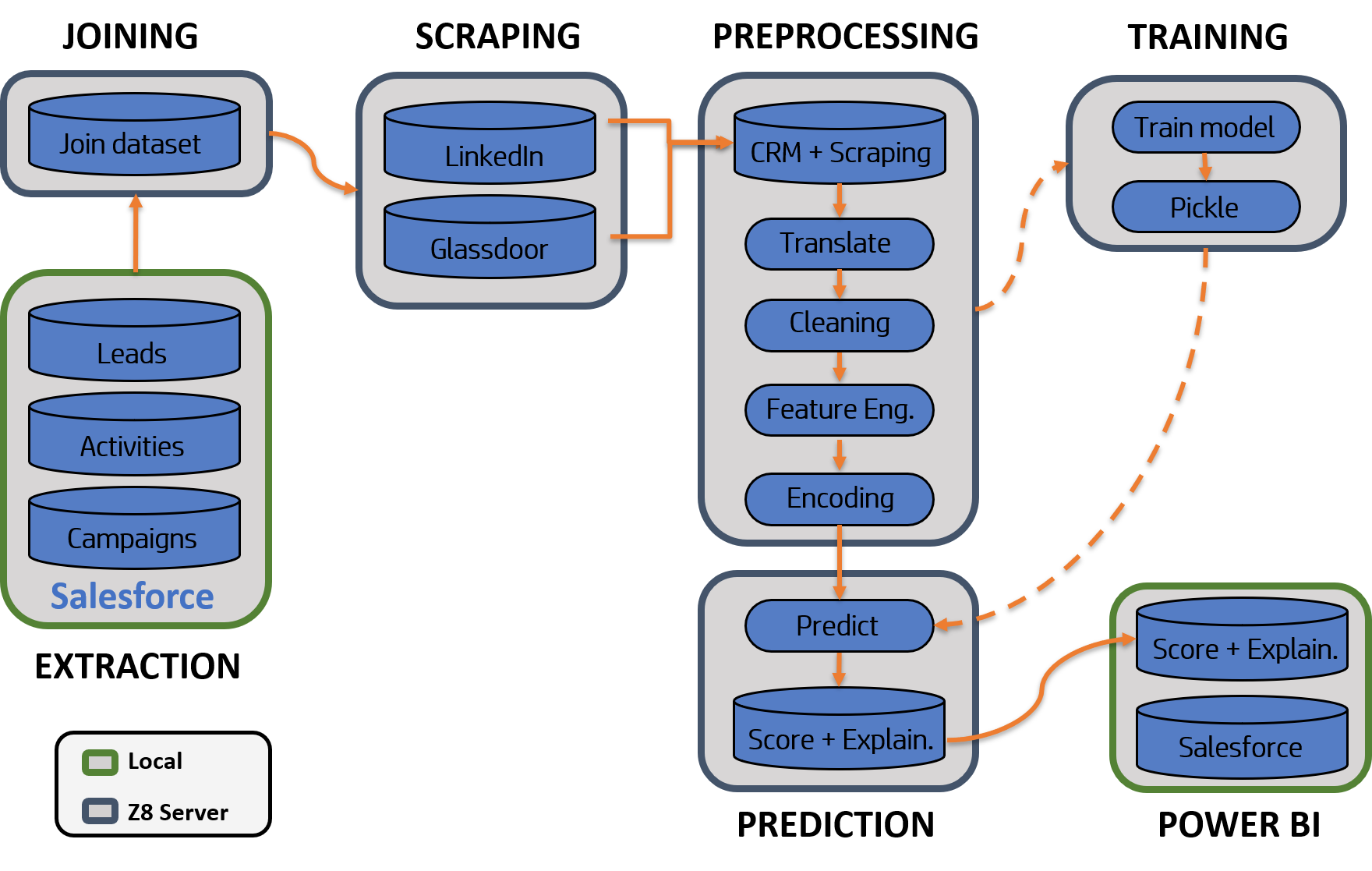
The pipeline developed is widely explained in the thesis file found in this repository. But the main structure of the pipeline is exposed below:

The pipeline consist of the following processes:
- Joining: First joining all the sources in one table, this is done in a Z8 server inside HP.
- Scraping: Web scraping techniques were used to enhance the information received from the company CRM.
- Preprocessing: Some of the scraped pages were not in English and hence, they needed to be translated. Along with the translation, other tasks such as data cleaning, feature engineering, and encoding were needed to assure the best possible dataset to feed the algorithm.
- Training: The model can be periodically retrained with a pipeline parameter. This training was developed on all the data to predict the score for just the leads that were not assigned to any state yet. The algorithm selected to do the predictions was an Extreme Gradient Boosting. The output of this training is a pickle file used to do faster predictions.
- Prediction: In this step, the score for each lead was output along with the explainability of the most important attribute for the decision with the LIME package.
- PowerBi: The file resulting from the prediction was retrieved from the server and put to a PowerBi so the whole organization can use the data from the scarping, scoring, and explainability algorithms.
Many organizations are still driven by intuition and experience-based decision making. With this type of decision-making, problems such as human bias, loss of experienced workers, and the reluctance to use more sophisticated information systems can be a severe problem. With the arrival of the era of data, companies have at their disposal more information than never before, but not many know how to use this resource to its full potential. In this work, we are going to develop a data science pipeline to predict the quality of the sales leads for the EMEA 3D sales department in HP, a project that aims to enhance the transition to a data-driven decision-making organization.
In order to solve this problem, the developed pipeline was focused on two tasks. The first, involved developing a web scraping tool to obtain information not previously available on the company database or that was very time consuming to acquire due to the size of the database, of more than 40,000 leads. And second, the training of a machine learning algorithm to predict a score quality together with an explainability of the main features of the decision for every lead.
The result of this process greatly impacted the business, all the knowledge was kept always in the company inside the machine learning model, and the explanations of each decision are making gain confidence in the model. Furthermore, the sales team used the score to make more data-driven decisions and save time by prioritizing the best quality leads. The accuracy of the trained Extreme Gradient Boosting algorithm to do the predictions proved to be a 13.45% improvement over the baseline model with a total accuracy of 0.94282 when tested on the test set.
Lastly, all these tasks were put together as a pipeline and uploaded to a server inside HP to execute the process automatically every day with minimal human intervention. The pipeline developed proved to give very positive results for the organization and further developments are being made to enhance the results.
Disclaimer: The data used for this project is highly sensitive and as part of the confidentiality agreement signed with HP, only minimal amounts of data with no customer details can be taken out of the company nor be externally used. As a result, no data exploration can be publicly shown. Due to this, only the output file with the predictions and explainability with no customer data can be exposed in this public domain. The other files have been left just with one or two lines to get the grasp of the fields in the dataset.
 https://github.com/jordisc97/MSc_Data_Science-Master_Thesis
https://github.com/jordisc97/MSc_Data_Science-Master_Thesis