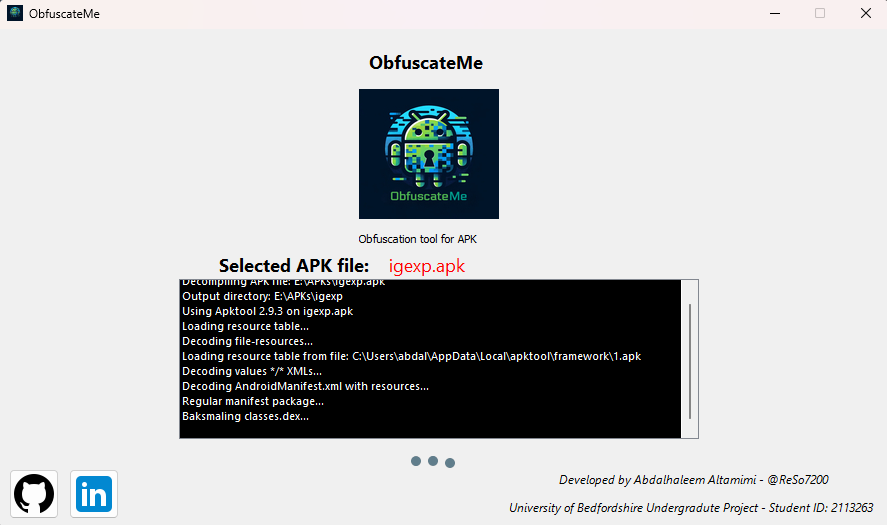
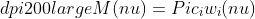Link to the article | 
This work has been published in the following article:
Toward standardization of Raman spectroscopy: Accurate wavenumber and intensity calibration using rotational Raman spectra of H2, HD, D2, and vibration–rotation spectrum of O2
Ankit Raj, Chihiro Kato, Henryk A. Witek and Hiro‐o Hamaguchi
Journal of Raman Spectroscopy
10.1002/jrs.5955
Set of functions in Python and IgorPro’s scripting language for the wavenumber calibration (x-axis) and intensity calibration (or correction of wavelength dependent sensitivity, i.e. y-axis) of Raman spectra. This repository requires the data on the rotational state (J), frequency, and the measured rotational Raman intensities from H2, HD, D2 and O2. Programs in Python and IgorPro are independent and perform the same job.
-
For wavenumber calibration, the pixel positions with error of rotational Raman bands from H2, HD, D2 and rotation-vibration bands from O2 are required, which can be obtained from band fitting. The code does Weighted Orthogonal Distance Regression (weighted ODR) for fitting x-y data pair ( corresponding to pixel – reference wavenumber), both having uncertainties, with a polynomial. Output are the obtained wavenumber axis from fit and an estimate of error.
-
For intensity calibration, the main scheme of the code is for the non-linear weighted minimization to obtain coefficients for a polynomial which represents the wavelength dependent sensitivity. The output is a curve extrapolated to same dimension as required by user for intensity calibration. An independent validation of the obtained sensitivity should be done for a measure of accuracy.
Intensity calibration
In any Raman spectrometer, light scattered by the molecules travels to the detector while passing through/by some optical components (for example, lens, mirrors, grating, etc..) In this process, the scattered light intensity is modulated by the non-uniform reflectance/transmission of the optical components. Reflectance and transmission of the optics are wavenumber dependent.
The net modulation to the light intensity, defined as M(ν), over the studied spectral range can be expressed as product(s) of the wavenumber dependent performance of the ith optical element as
 = \Pi c_{i}w_{i}(\nu)")
Here, ci is a coefficient and wi(ν) is the wavenumber dependent transmission or reflectance of the ith optical component.
In most cases, determining the individual performance of each optical element is a cumbersome task. Hence, we limit our focus to approximately determine the relative form of M(ν), from experimental data. By relative form, it is meant that M(ν) is normalized to unity within the studied spectral range. If M(ν) is known, then we can correct the observed intensities in the Raman spectrum by dividing those by M(ν). In general, this is the principle of all intensity calibration procedure in optical spectroscopy.
In our work, we assume M(ν) ≅ C1(ν) C2(ν) / C0(ν) [The wavenumber dependence in not explicitly stated when C0, C1 and C2 are discussed in the following text. ] The three contributions, C0(ν) to C2(ν) are determined in two steps in this analysis.
- In the first step, (C0 / C1) correction are determined using the wavenumber axis and the spectrum of a broad band white light source. (See example)
- C2 is determined from the observed Raman intensities, where the reference or true intensities are known or can be computed. This can be done using (i) pure-rotational Raman bands of molecular hydrogen and isotopologues, (ii) vibration-rotation Raman bands of the same gases and (iii) vibrational Raman bands of some liquids.
The multiplicative correction to the Raman spectrum for intensity calibration is then : (C0 / C1C2)
The present work is concerned with the anti-Stokes and Stokes region (from -1100 to 1650 cm-1). For a similar analysis for the higher wavenumber region (from 2300 to 4200 cm-1) see this repository and article.
Wavenumber calibration :
Fit of the reference transition wavenumbers against the band position in pixels is performed to obtain the wavenumber axis(relative).
- S. B. Kim, R. M. Hammaker, W. G. Fateley, Appl. Spectrosc. 1986, 40, 412.
- H. Hamaguchi, Appl. Spectrosc. Rev. 1988, 24, 137.
- R. L. McCreery, Raman Spectroscopy for Chemical Analysis, John Wiley & Sons, New
York, 2000.
- N. C. Craig, I. W. Levin, Appl. Spectrosc. 1979, 33, 475.
Intensity calibration :
Ratio of intensities from common rotational states are compared to the corresponding theoretical ratio to obtain the wavelength dependent sensitivity curve.
- H. Okajima, H. Hamaguchi, J. Raman Spectrosc. 2015, 46, 1140. (10.1002/jrs.4731)
- H. Hamaguchi, I. Harada, T. Shimanouchi, Chem. Lett. 1974, 3, 1405. (cl.1974.1405)
Wavenumber calibration
- List of band positions and error (in pixels) of rotational Raman spectra of H2, HD, D2 and rotational-vibrational Raman spectra of O2.
Intensity calibration
- List of all data required : rotational state (J), experimental band area ratio (Stokes/ anti-Stokes), theoretical band area ratio (Stokes/anti-Stokes), transition frequency (Stokes) in cm-1, transition frequency (anti-Stokes) in cm-1 and the weight (used for fit). For O2, when using the vibration-rotation transitions (S1- and O1-branch), include the data and the frequencies for these transitions. All of the above correspond to pair of observed bands originating from a common rotational state.
See specific program’s readme regarding the use of the above data in the program for fit.
- Set of Igor Procedures
- A Python module
for performing non-linear fit on the above mentioned data set to obtain the wavelength dependent sensitivity.
Additionally, programs to compute the theoretical pure rotational Raman spectra (for H2, HD and D2) are also included.
Clone the repository or download the zip file. As per your choice of the programming environment ( Python or IgorPro) refer to the specific README inside the folders and proceed.
Comments
-
On convergence of the minimization scheme in intensity calibration : The convergence of the optimization has been tested with artificial and actual data giving expected results. However, in certain cases convergence in the minimization may not be achieved based on the specific data set and the error in the intensity.
-
Accuracy of the calibration : It is highly suggested to perform an independent validation of the intensity calibration. This validation can be using anti-Stokes to Stokes intensity for determining the sample’s temperature (for checking the accuracy of wavelength sensitivity correction) and calculating the depolarization ratio from spectra (for checking the polarization dependent sensitivity correction). New ideas regarding testing the validity of intensity calibration are welcome. Please give comments in the “Issues” section of this repository.
Non-linear optimization in SciPy : Travis E. Oliphant. Python for Scientific Computing, Computing in Science & Engineering, 9, 10-20 (2007), DOI:10.1109/MCSE.2007.58
Matplotlib : J. D. Hunter, “Matplotlib: A 2D Graphics Environment”, Computing in Science & Engineering, vol. 9, no. 3, pp. 90-95, 2007.
Orthogonal Distance Regression as used in IgorPro and SciPy : (i) P. T. Boggs, R. Byrd, R. Schnabel, SIAM J. Sci. Comput. 1987, 8, 1052. (ii) P. T. Boggs, J. R. Donaldson, R. h. Byrd, R. B. Schnabel, ACM Trans. Math. Softw. 1989, 15, 348. (iii) J. W. Zwolak, P. T. Boggs, L. T. Watson, ACM Trans. Math. Softw. 2007, 33, 27. (iv) P. T. Boggs and J. E. Rogers, “Orthogonal Distance Regression,” in “Statistical analysis of measurement error models and applications: proceedings of the AMS-IMS-SIAM joint summer research conference held June 10-16, 1989,” Contemporary Mathematics, vol. 112, pg. 186, 1990.
Please use “Issues” section for asking questions and reporting issues.
This work has been published in the following article:
Toward standardization of Raman spectroscopy: Accurate wavenumber and intensity calibration using rotational Raman spectra of H2, HD, D2, and vibration–rotation spectrum of O2
Ankit Raj, Chihiro Kato, Henryk A. Witek and Hiro‐o Hamaguchi
Journal of Raman Spectroscopy
10.1002/jrs.5955
Other repositories on this topic :
The present repository is concerned with the anti-Stokes and Stokes region spanning from -1040 to 1700 cm-1 using H2, HD, D2 and O2. In a different work, spectral region in the higher wavenumber(from 2300 to 4200 cm-1) was investigated.
Accurate intensity calibration of multichannel spectrometers using Raman intensity ratios
Ankit Raj, Chihiro Kato, Henryk A. Witek and Hiro‐o Hamaguchi
Journal of Raman Spectroscopy
10.1002/jrs.6221
See online repository IntensityCalbr and the above article (JRS.6221) for more details.